Databases and SiteCatalyst
Having gone from writing really interesting stuff about Twitter, slashdot, Digg and other ‘fun’ things, I think it is about time I got back to the boring old stuff. That is to say, lets go back to looking at Omniture SiteCatalyst and what I have learned in the last month and a half. You may remember I started a couple of weeks ago and posted on the methods that I was going to use. This week, to help explain better what I have been looking at, I am going to start with a little database 101.
Just in case you weren’t paying attention in year 8 IT classes (or whatever it is now called these days) databases are a way for you to store records about objects in a structured way (or a model). I’m sure you all remember looking at Microsoft Works database and thinking about creating a database of films that you’d seen where you’d put the lead star, the genre and a rating, so that in the future you’d be able to remember whether it was worth it or not.

Well most databases follow this model. You have a series of fields that you can input data into and then you can sort in various different ways. It’s a bit like having a big spreadsheet in a way.
However it gets a bit more complicated by ‘relational databases‘. I’m going to attempt to steer clear of the technical side of this, so don’t blame me if this is completely over simplified. Essentially a model where you have all your fields in one table doesn’t work in most case. This is because there is an assumption that either you could create a table big enough would be difficult or that the data is inputted in a non linear way. Eg when you’re filling in a car insurance form online, there may be many pages to complete. Each page will probably correspond to a different database table in the background.
These tables then have to be linked and this is done usually through some sort of key. This key will allow the database to work out which fields in each table can be linked. So if we continue with our car insurance idea, then there will be one table for the car details, one for the person being insured and these will have a common element allowing the linking of the two tables to see who the person is and what car they are being insured on.
There is another reason why you may use a relational database and that is because one field on one table, may relate to many fields on another table. In our car insurance example the person being insured may have had several accidents in the past that need to be counted, so the table for past claims could have many fields relating to one person. Again, these will need a common key for the tables to be related. It’s lucky I chose a car insurance theme at this point and not some sort of marriage theme, because things could be going horribly wrong at this point.
Of course there is also the possibility of a many to many relationship. Which is where my car insurance idea breaks down, but you get the picture.
How does this relate to web analytics? Well our web analytics tools are just big databases with fancy front ends. They store the data in a big warehouse that if you have the right tools you should be able to access in any way you could possibly wish. However the front ends tend to give you a good description of how they work in the back end.
For this we see that we have a series of custom traffic variable reports. If you can persuade (cf pay) Omniture to allow you, you can get visits to each of your custom traffic variables as well as page views (and a load of other metrics too). Your custom traffic variables are coded on the page (they’re your sprops). They’re fairly basic – think of your page name, which is effectively the first sprop you’ll want to name.
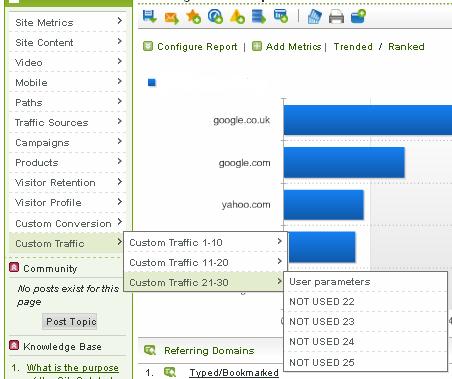
Visits remember is a one to many relationship with page views. However the correlation reports that you run through your sprops work in a slightly different way. They are one to one relationships, hence visits make a little less sense in this case and would take much more processing power. For a recap, you use data correlations to link one custom traffic variable to another. This means you can say if custom traffic variable 1 was equal to ‘a’, tell me what the values of custom traffic variable 2 were (and depending on your depth, you could even drill down deeper).
Still making sense? So if you can only get page views (I think I’d prefer it if they called these ‘instances’, but its a bit of a muchness), how do you use this data correlation? You have to use it in cases when you are only interested in things that related to page views. Or where the metric didn’t matter. Eg what pages did a user look at when logged on, if you set up your custom traffic variable to record on every page the username or the user status, you work out for each username/user status what pages those people/statuses had looked at.
So data correlations are useful in certain circumstances. In other circumstances what you actually want to be able to do is drill down. In this case you need to not look at correlations but at classifications. Classifications work in a slightly different way in that you define them after you have collected the data. In SiteCatalyst these are described by SAINT.
With SAINT, you can take your database table (eg one of your custom traffic variables) and add additional fields to it that you populate after the data is collected. Eg if you have a series of usernames that you collect in a custom traffic variable, you could take a table out of your existing database with usernames and what company they related to and then you could upload it into SiteCatalyst.

Alec,
Some really useful stuff here about SiteCatalyst and very pertinent.
As an agency I think we will have a small problem convincing our customers about the price of the product (mainly because Omniture do not publish prices and their model rel on high traffic).
I have no doubt of the importance of analytics to these businesses but it seems a lot of phone calls need to occur between their support and the IT teams of the sites. Is that your experience? If you need to correlate reports it seems to be always a phone call and extra cost…
It’s probably not odd that Omniture don’t publish their prices. I know that if they did then they might end up with a load of customers narked because they think they are being over charged. The beauty (for Omniture) of being able to quote on an individual basis is that some clients will pay more for a package than others depending on their negotiating skills.
For an agency though, this can be annoying, because you want to be able to quote to your clients what it would cost to do the additional requirements they have.
However a lot of SiteCatalyst can be done out of the box. The real issue is that many companies don’t put enough thought into set up and upkeep initially and that means that work arounds are needed or historical data is lost. Quite often management are happy for the incorrect reporting to be continued as long as it is consistent. This is when eventually you need to get a specialist or an agency to come in and do the technical optimisation of the tool (rather than of the site, which is what we’d really like to be doing).